Email caching
As most interaction with imap is for lists and summary information about emails rather than the emails themselves it makes sense to optimise the database to return that information quickly. As you can see from the following schema there are more tables caching information about an email than storing the email itself.
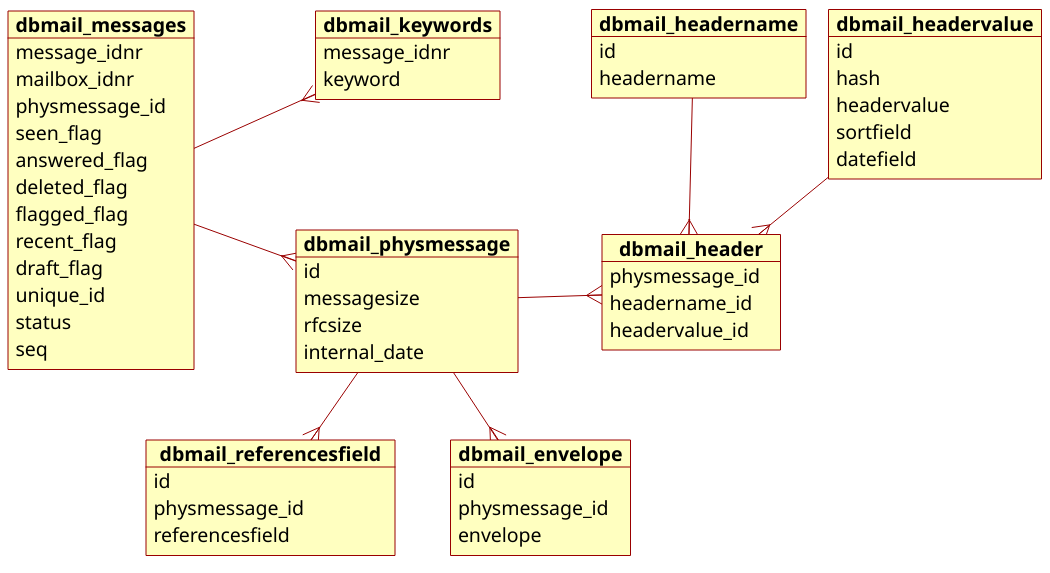
When an incoming email arrives, dbmail extracts various headers and adds it to the cache.
There are also a few database views for frequently used header fields:
- dbmail_ccfield
- dbmail_datefield
- dbmail_fromfield
- dbmail_subjectfield
- dbmail_tofield
In addition to a number of header fields that are essential such as the date and subject, there are also any number of additional fields that may be added. The default setting for header_cache_readonly is to not add new headers so if you want to cache a header add it to the dbmail_headername table. There is a unique constraint on dbmail_header so if an email includes more than one header with the same name, duplicates will be logged as warnings that can safely be ignored.
Database schema
| Table.Column | Description |
|---|---|
| dbmail_headername.id | Primary key |
| dbmail_headername.headername | Name of the header |
| dbmail_headervalue.id | Primary key |
| dbmail_headervalue.hash | Cryptographic hash |
| dbmail_headervalue.headervalue | Value of the header |
| dbmail_headervalue.sortfield | A sane representation of the value |
| dbmail_headervalue.datefield | If the value is a date, it is converted to: "%Y-%m-%d %H:%M:%S |
| dbmail_header.physmessage_id | Reference to the message |
| dbmail_header.headername_id | Reference to the header name |
| dbmail_header.headervalue_id | Reference to the header value |
| dbmail_envelope.id | Primary key |
| dbmail_envelope.physmessage_id | Reference to the message |
| dbmail_envelope.envelope | A summary of the email rfc 822 headers aka envelope |
| dbmail_referencesfield.id | Primary key |
| dbmail_referencesfield.physmessage_id | Reference to the message |
| dbmail_referencesfield.referencesfield | The reference to another email |